The latest Barbie fad and website SEO scores have one thing in common—a lot of people have trouble when trying to articulate about them out loud.
Let’s clear up the confusion.
Barbie has nothing to do with SEO. It is, for most intents and purposes, an inanimate doll.
But more about that later.
A website SEO score, on the other hand, has everything to do with presenting your site in the best possible light for snatching high search result rankings from right under your competition’s puffing, pinkish nostrils.
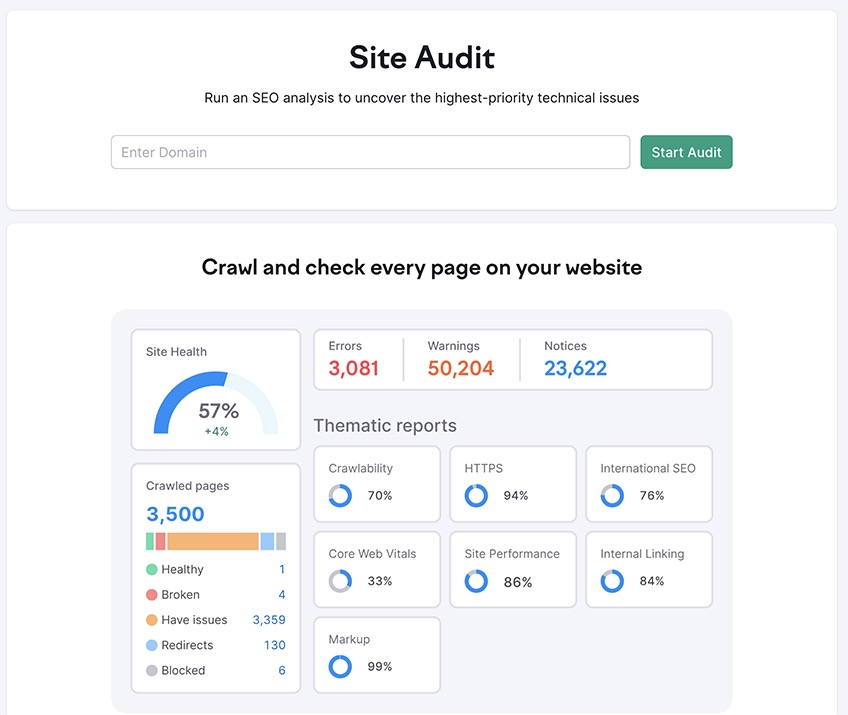
There are several SEO score tools on the market, many of them measuring your site’s overall search engine viability on a 0-100 percentage scale. Generally speaking, you should strive to achieve a website SEO score of 96% or higher.
Achieving scores higher than 96% will often have little to do with SEO and more to do with off-site factors such as brand popularity, search engine partnerships, or even—and god forbid the billionaires overhear this—the tiniest stroke of luck.
In any case, it’s hard to obtain a meaningful bump in the rankings once you’ve already reached 96%, so you can be almost sure that SEO is not what’s impeding your ranking efforts beyond that point.
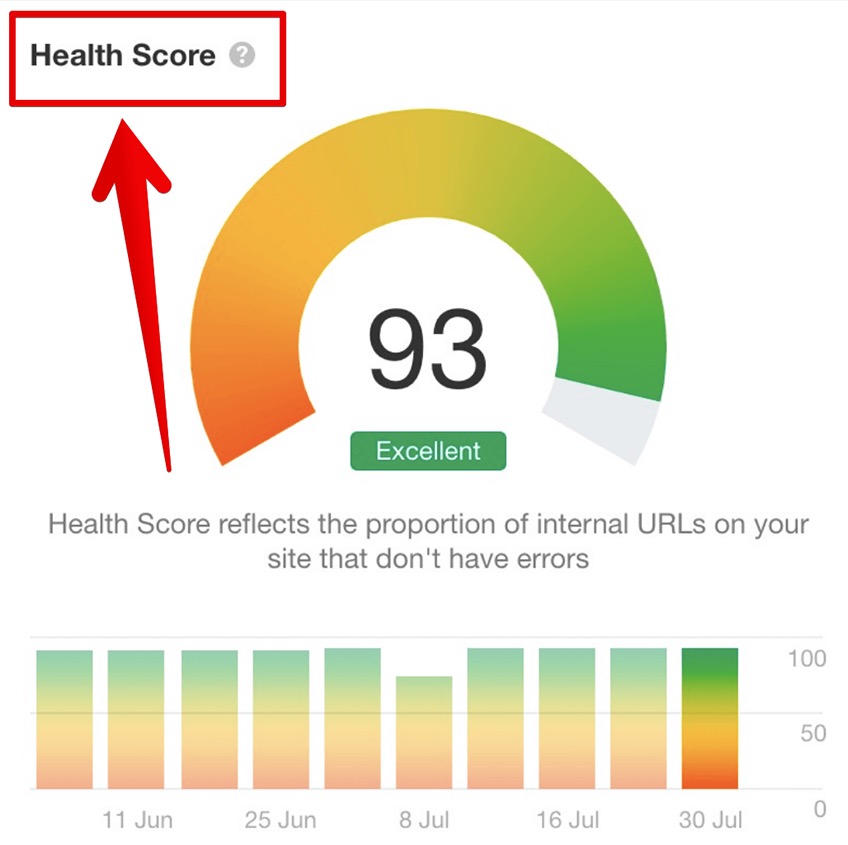
Alternatively, other website SEO scores come in all shapes and sizes—and names.
Depending on your preferred SEO tool, this same collection of metrics might be called your Site Health Score, Health Score, Site Rating, Site Health, Site Health Status, or a completely different name.
These tools may also use different grades for your website, including:
- Letter grades (A-F)
- Numeric or percentage scales (0-5, 0-100)
- Evaluative or descriptive scales (from Poor to Excellent, Unsatisfactory to Perfect, or from Are you even trying to Chef’s kiss)
Regardless of their branding or name, the majority of these website SEO score tools look at the same fundamental elements when scoring a site.
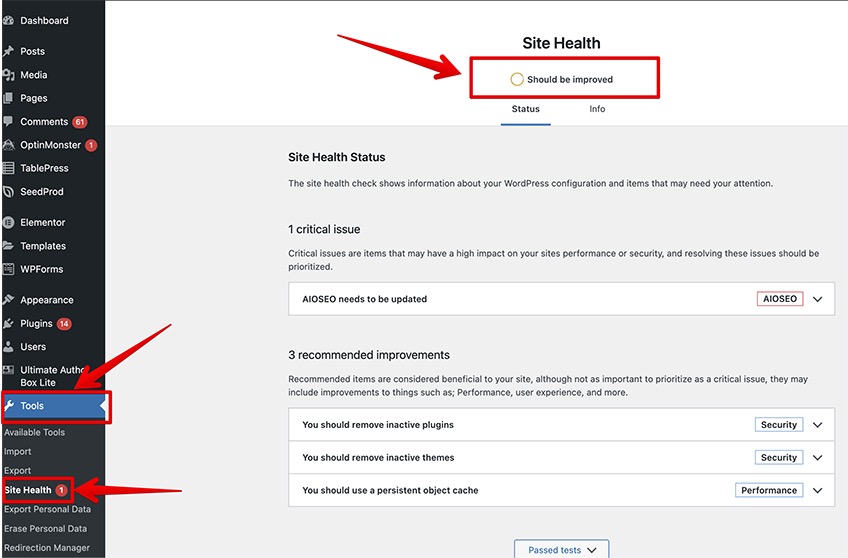
To access a detailed view of the Site Health Status in WordPress, go to the left-hand side (while logged in as an administrator), click Tools, and then click Site Health.
But we are getting ahead of ourselves.
What Is a Website SEO Score?
A website SEO score is a collection of metrics that sums up how well your website performs in terms of rankings, search engine optimization, and online visibility.
The higher your site’s score, the better its pages will perform in search engine results pages (SERPs). A lower website SEO score means that your site is not technically optimized and it reduces your chances of showing up higher than your competitors in search results.
As with most things related to SEO, website scores are not immune from controversy. Some experts believe that website SEO scores are not directly correlated with performance in the SERPs, while others disagree.
Nevertheless, most SEO experts would agree that SEO scores indirectly contribute to search engine visibility, which is a different way of saying that SEO scores are a good approximation of how well your website will perform in the arena of Google Search.
Controversy aside, website SEO scores can be broken down into five main segments:
96%-100% – Perfect
Your technical optimization is as good as it gets. Further SEO optimization may not be worth the hassle for any future micro wins you can potentially get out of it, although it doesn’t hurt to try if you’re a massive brand like Nike or PCMag.
80%-95% – Good
Your website is most likely performing well, but it can do better. You’re free to address the most pressing errors (redirects, 404 errors) and check for site structure related things (sitemap, categories, tags, URL structure, page hierarchy, slugs) to improve the crawlability of your site and the availability of your pages.
60%-79% – Passable
This is where it gets tricky. If users encounter bad UX between 40% and 20% of the time that they’ve spent on your site, it means there may be something wrong.
At this time, it wouldn’t hurt to consult a technical SEO expert to guide you through the full SEO optimization process so you can identify and address the errors without repeating them moving forward.
30%-59% – Needs Improvement
If you’re using a custom-made website (coded from scratch), it’s probably time to go back to the drawing board and audit the website code to resolve the issues.
If that proves too difficult, switching to a popular content management system (CMS) and web hosting platform could solve these issues at the potential cost of losing existing traffic and introducing further headaches in terms of website and domain migration.
If you’re already using a popular CMS and are still getting error-ridden results, consider addressing the issues quickly before your website and its pages have almost no shot at appearing in search results.
0-29% – Unsatisfactory
If your site scores this low, it may as well be nonexistent in the eyes of Googlebot.
There are three courses of action for an outcome of this gravity.
- Migrate your site to a different environment (including theme, CMS, and hosting provider)
- Nest your old domain under the domain of a different project (either as a subdomain or a subfolder) to salvage any existing link juice
- Go over the report and try to solve all of the errors one at a time—without ripping your (or any Barbie doll’s) hair out
It’s important to note that website SEO scores and the tools that come up with them are not always perfect. They are based on code that typically checks for the presence or absence of certain elements and adjusts the final score based on that.
Some of the more powerful tools may use more complex algorithms than others, but the SEO scores should always be considered in the context of an overall site audit, and not as a separate metric devoid of context.
For example, Semrush determines your site’s SEO health based on both the number of pages that show errors and the number of pages that are being crawled in the audit.
The formula to calculate this is as follows: (1 – (URLs with errors / crawled URLs)) x 100.
As such, if you decide to audit 100 pages, and 50 of those pages have errors, then your site health score would be (1 – (50 / 100)) x 100, or 50%.
Yikes!
The thing is, even if the remaining 50 errorless pages perform really well for you, you’d still have a score of 50% for that particular audit. To put it simply, that’s why these numbers and scores are not as useful without considering the full context of the site audit.
Thus, if you have the crawl budget, it’s important to audit your entire website to get a more accurate representation of everything that’s going on under the hood, both good and bad.
How To Get a Perfect Score for Website SEO for Free
Far from being a mere vanity metric, reaching that elusive 100% website SEO score could also catapult your website into the uppermost layers of the search ranking stratosphere.
Here are five actionable tips on how to do it without spending a dime.
1. Sign Up for a Free Trial of SEMRush
Before creating a Semrush account and signing up for a free trial, you will need to decide which website you’ll want to perform the site audit on.
Performing a thorough site audit requires a crawl budget. The crawl budget determines the number of pages on which (and sometimes the processing speed at which) to perform the audit.
If your site has fewer than 100 pages, then you don’t have to worry about the crawl budget. In fact, you won’t even need to start a free trial because you can perform the audit with a completely free Semrush account.
To avoid any confusion, let’s differentiate between a free trial and a free account:
- Free trial—Full Semrush functionality for seven days
- Free account—Limited Semrush functionality forever
To find the number of pages on your website—particularly pages that are indexed by Google—simply go to Google Search and type site:example.com in the search bar.
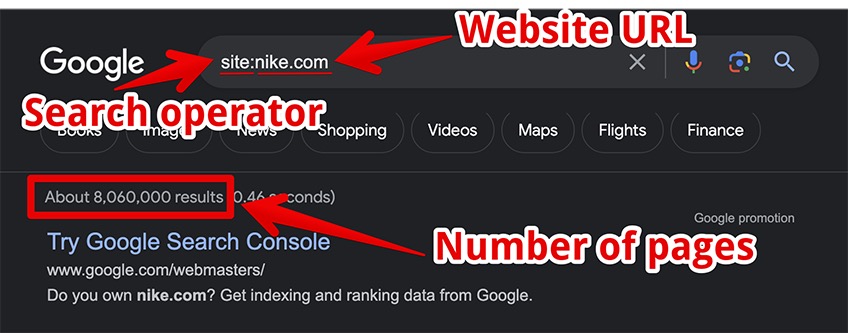
The “site:” part is considered a search operator. The “example.com” part refers to the full URL address of your website.
Once you’ve confirmed your site’s total page number is over 100, it’s time to sign up for a free trial—and here’s how.
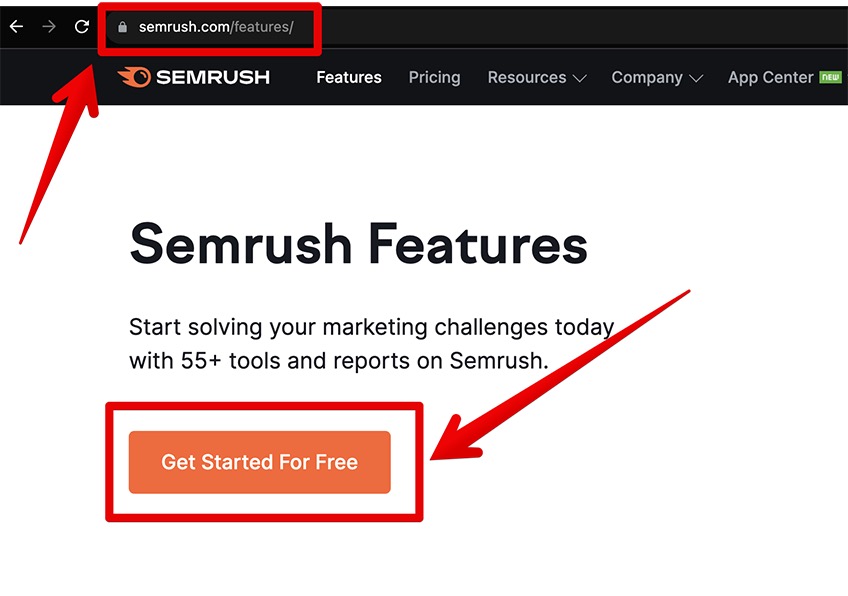
Navigate to Semrush Features and click Get Started for Free.
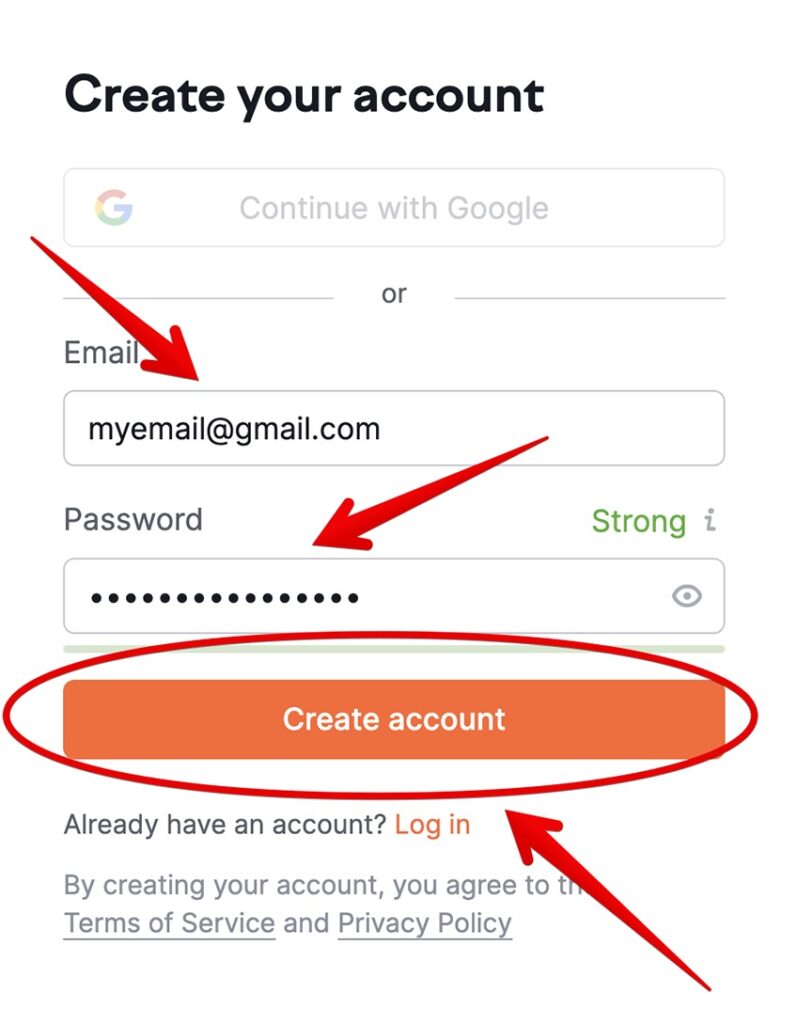
Next, enter your preferred email, choose a strong password, and click Create Account.
You should then receive a confirmation email with a number in the email body. Enter that number in the required field on Semrush and proceed to the next step.
You’ll then be presented with several options. Click the option that denotes a free trial, enter your credit card number (you won’t be charged after accepting the terms), and sign up for the seven-day free trial.
Boom! You can now perform a full site audit without limitations.
2. Run Site Audit
Go to Semrush Site Audit and pick the Site Audit option from the On Page & Tech SEO menu.
Enter the full domain name in the site audit bar (make sure to enter the domain name exactly as it’s shown in the URL address bar), and click Start Audit.
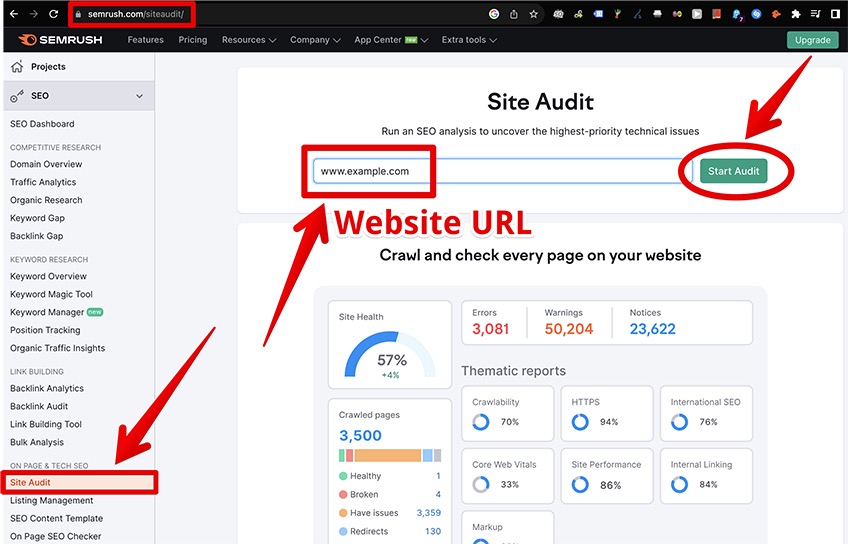
You will then be presented with the following menu.
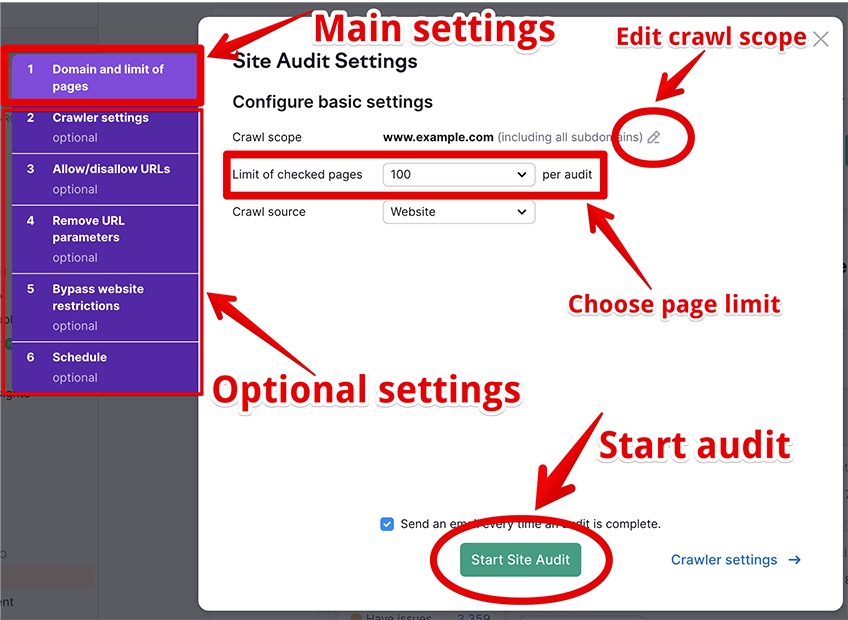
There are a couple of options that you can play with here, including the main settings and the optional settings.
The main settings include three mandatory parameters for setting up the site audit.
- Crawl scope—Determines the specific domain, subfolder, or subdomain to crawl. The default option allows you to crawl the entire root domain, including all subdomains and all subfolders nested under the root domain.
- Limit of checked pages—Here you can select the number of pages to crawl from the pre-existing options, or you can enter a custom amount of pages to audit by picking the Custom option from the drop-down menu.
- Crawl source—Configures the main crawl source for the site audit. You can choose between Website, a file of URLs, Sitemap by URL, and Sitemap on site.
The following optional settings include many parameters for a more granular approach to your website audit.
2.1 Crawler settings
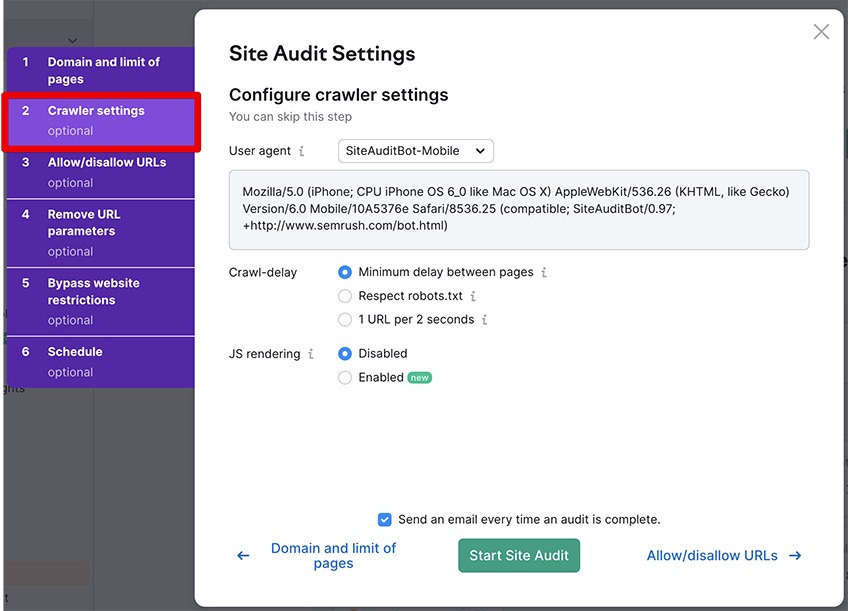
This option allows you to choose the user agent to crawl your website, either the desktop or mobile version of SemrushBot or GoogleBot.
You can also configure a crawl delay in your robots.txt file, including a Respect robots.txt option for reducing the probability of encountering speed issues for the real users on your site.
2.2 Allow/disallow URLs
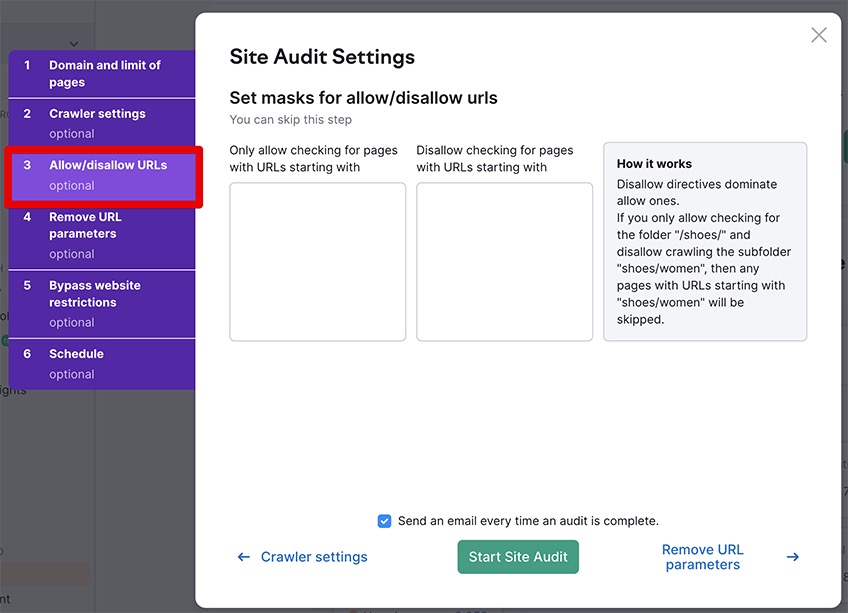
Here you can include specific URLs to allow or disallow the bots from crawling pages of your choosing.
If you want to crawl a specific URL, you will need to enter everything after the Top-Level Domain.
2.3 Remove URL parameters
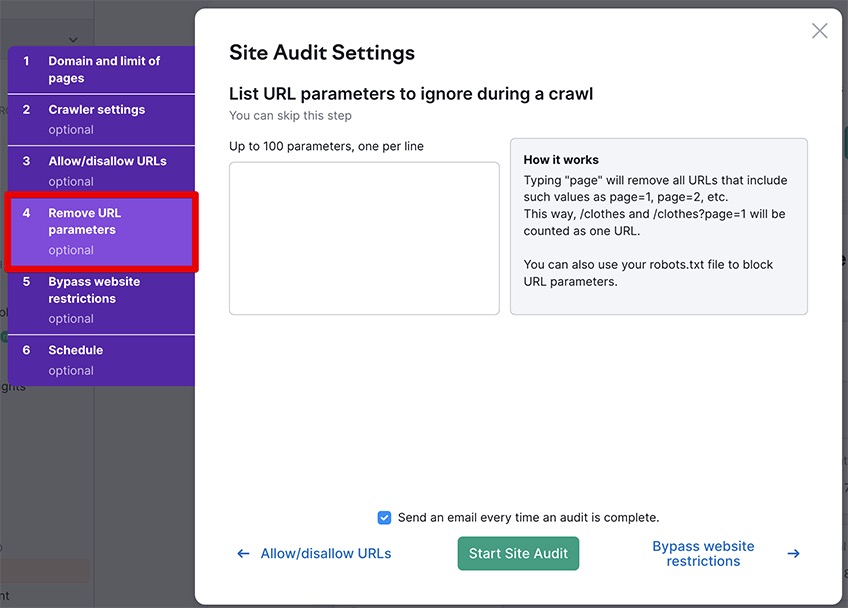
URL parameters are elements that modify the original URL address outside of the main site hierarchy.
Common URL parameters include UTM (tracking), SORT (reordering), PAGE (paginating), LANG (translating), and more. Setting these rules allows you to exclude any undesirable URL parameters from the site audit.
2.4 Bypass website restrictions
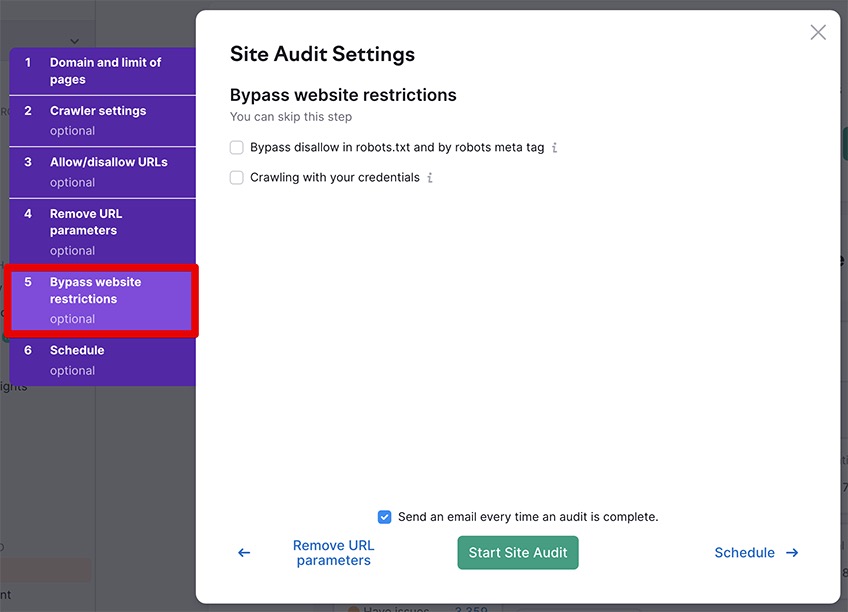
Here you are offered to bypass the disallow in robots.txt and the robots meta tag, as well as to perform the audit using your credentials to bypass password-protected areas on your site.
2.5 Schedule
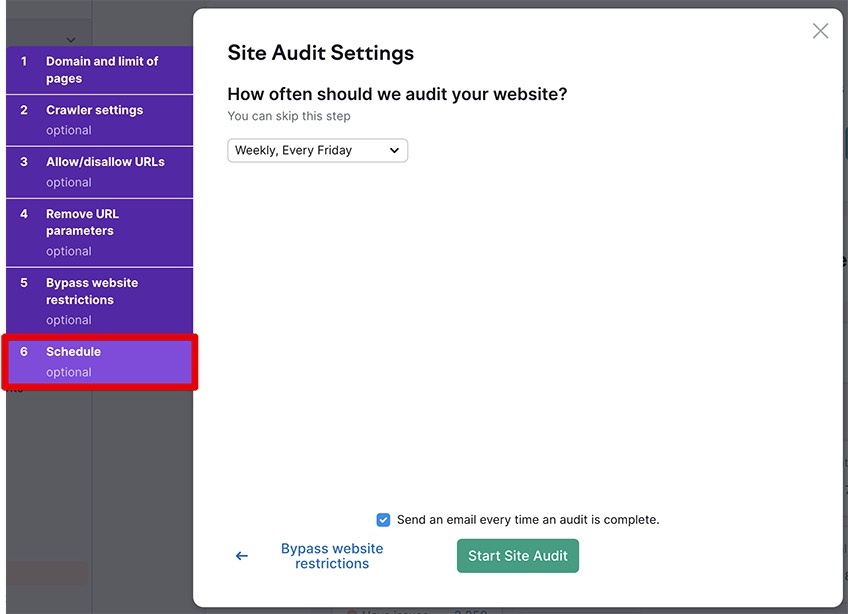
This final option allows you to schedule the site audit weekly, daily, or run the audit as a one-time event.
Once all of that is sorted out, click Start Site Audit.
3. Address Issues
Once your audit is complete, you’ll find it tucked under the Projects tab in Semrush. This is where you’ll see all the pesky issues it uncovered that prevent your site from conquering Google Search.
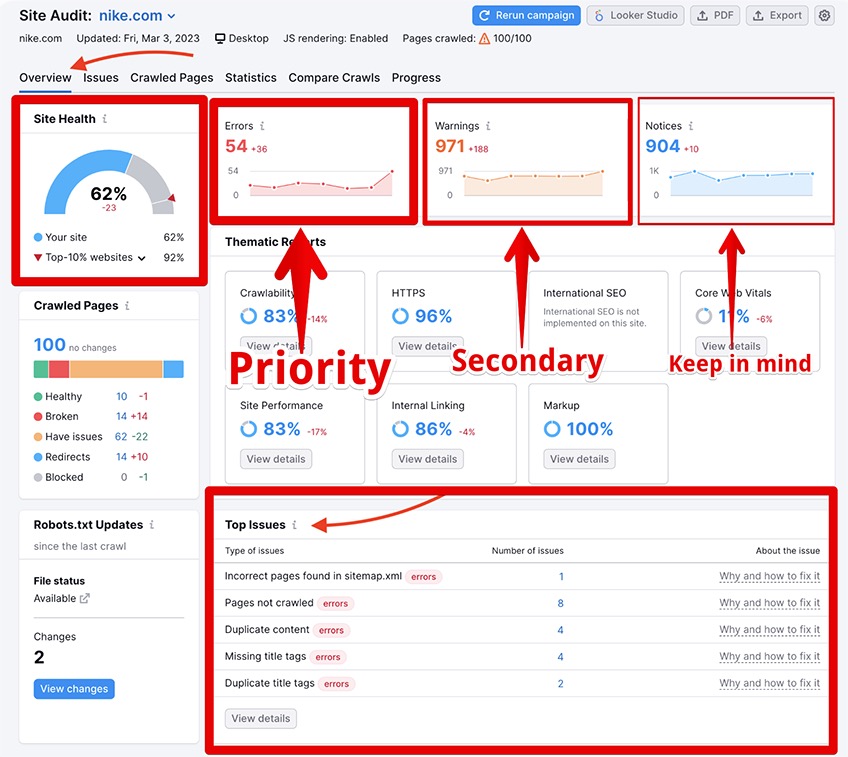
Depending on the number of issues and the severity of your site health, it can be wise to prioritize your work in the following order:
- Errors
- Warnings
- Notices
Errors are the primary issues that you’ll need to address immediately. Consider these your utmost priority.
Warnings are secondary issues that typically require consistent management to solve or prevent from happening in the future.
Notices aren’t considered issues, but Semrush suggests resolving them once all of your errors and warnings are properly done and dusted.
To access the full error report, click the number under the Errors title.

You will be presented with a full error report, explanations, and suggestions on how to fix said errors.
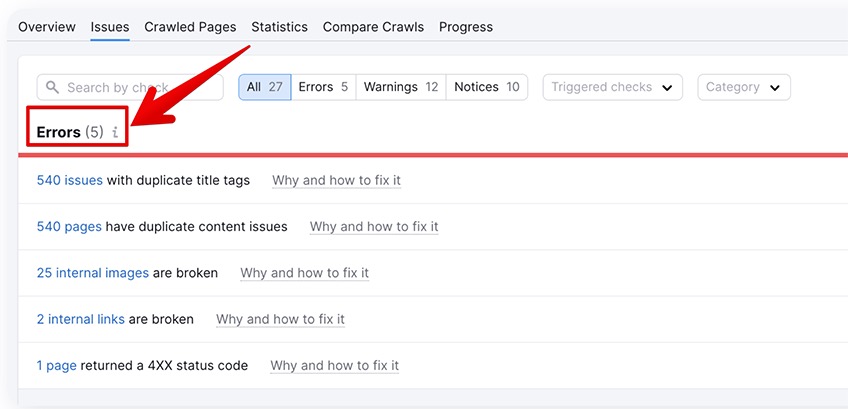
Some of the most common errors that come up have common solutions to go with them.
3.1 Incorrect pages found in sitemap.xml
The sitemap.xml is a file that contains all the pages that are intended for your audience to access. If out of order, it can confuse the search engine bots and skew the indexing results, ultimately messing up the crawlability of your site.
Problem: Your sitemap.xml file contains duplicate URLs, different URLs that lead to the same pages (pages featuring identical content), or pages that return a non-200 status code (301, 302, 404, 410, 500).
Solution: Review your sitemap.xml file, looking out for redirected pages, non-200 pages, and non-canonical pages.
It’s important to identify the error-stricken pages and either:
- Disallow the crawlers from accessing them in the robots.txt file (if they aren’t meant to be accessed)
- Fix the server response to show a 200 status code (if they are meant to be accessed)
3.2 Pages returned 4XX status code
Problem: A 4xx error (400, 401, 403, 404) occurs, suggesting that a page doesn’t exist, has restricted access, or a crawler can’t access it.
This usually happens for one of the following reasons:
- Broken links
- Server overload or misconfiguration
- DDoS protection
- URL misspelling (on the end user’s side)
Solution: Identify the error pages and remove all links that lead to those pages. If you’re keen on keeping these links, consider changing them to point to another resource on your site.
On the off-chance that the 4xx pages still work when accessed with a browser—meaning they are incorrectly picked up as errors—consider introducing a crawl-delay parameter in your robots.txt file to avoid frequent crawling of the flagged pages.
If that doesn’t work, you may want to contact your web hosting platform.
3.3 Internal links are broken
Problem: Hyperlinks on your site lead users to pages that don’t exist, whether pages on your site or pages on other websites.
If search engine crawlers detect a large number of broken links, there is a high probability that your site won’t do well in the SERPs.
Solution: Identify all of the broken links and apply the necessary fixes.
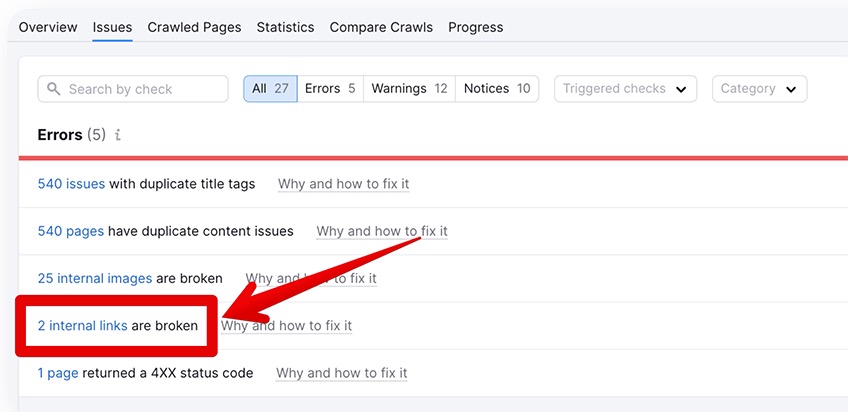
In Semrush, clicking on X internal links are broken will open up a section where you can fix your internal broken links. You’re free to replace existing hyperlinks with different ones, but more on this later.
Alternatively, you can also choose to remove the affected links, but doing so may negatively impact your internal linking hierarchy—and you may inadvertently remove hyperlinks that were part of paid partnerships or guest posting opportunities.
If some of the outbound links still work when accessed from a browser, consider notifying your webmaster about the error.
3.4 Pages have a slow load speed
Problem: Your site audit returns a large number of slow-loading pages. This negatively impacts the UX and could decrease your conversion rates.
Solution: Dive straight into your website’s code and try to identify the culprits. Keep in mind that the Semrush crawler only measures the load time of the “barebones” HTML code and disregards images, CSS, and JavaScript.
Other common issues that are known for causing slow load times could be your web server, website theme, and the utilization of content delivery networks—among a plethora of third-party online services.
In that case, consider contacting your third-party providers for additional information.
3.5 Structured data item is invalid
Problem: Your site doesn’t properly follow the universal format that helps both crawlers and users to better understand the content on your page.
Usually, pages with implemented structured data are the preferred option for users relative to non-structured pages.
Solution: Use Google’s rich results tool to check if your page correctly implements structured data. More on that later.
3.6 AMP analysis
Accelerated Mobile Pages (AMP) is an open-source framework that offers to build mobile-friendly websites that load instantly.
AMP is not a requirement for SEO, but it’s something to consider if you can spare the extra time.
4. Address On-Page SEO
On-page SEO is not synonymous with the Semrush Warnings tab. Warnings are issues of secondary importance that—either by chance, fate, or quantum mechanical fluctuations—happen to feature a subset of issues that belong to the overarching set of on-page SEO.
There’s a number of common warnings that Semrush will flag, so take note of their solutions.
4.1 Issues with blocked internal resources in robots.txt
Problem: Some of your resources, such as images, CSS, or JavaScript code are mistakenly blocked from being crawled by bots. This hiccup can lead to a significant loss in search traffic.
Solution: Doublecheck your robots.txt file for a “disallow” rule corresponding to those elements. If you find that certain resources are blocked when you believe they should be crawled instead, change or remove the “disallow” directive.
For more information, check out this detailed Google guide on robots.txt best practices.
4.2 Pages have a low text-to-HTML ratio
Problem: The amount of code for one or more of your pages significantly outweighs the amount of text on its corresponding page(s).
Lately, Google has been putting a bigger emphasis on useful pages with a substantial amount of content, and other search engines have been following this example.
The recommended text-to-HTML ratio should be 10% or more, and any page that contains less than 10% will get flagged by SemrushBot.
Solution: Compare the size of your page’s featured text against the code for that same page. If the code exceeds the text in terms of size, length, or both, consider optimizing your page’s HTML code or adding more relevant text to the page.
Just remember that less code usually means faster page load times, which translates to improved SEO rankings across the board.
4.3 Pages are missing meta descriptions
Problem: Users are discouraged from clicking on your page due to missing or poorly auto-generated meta descriptions.
Meta descriptions are technically not part of on-page SEO, but for all intents and purposes, they hold an important role in the success of a metric called click-through rate (CTR). This measures the number of times a link has been clicked on relative to the number of times that link has been shown in the search results.
If the majority of your commercial pages are missing meta descriptions, Googlebot will pull up the closest thing resembling a meta description from somewhere inside your page. If you don’t have an apt text for Googlebot to substitute the missing meta description, your page might end up looking weirdly out of place in the SERPs.
This can discourage the users from clicking on your page, which is a signal that your page is not trustworthy to be shown in the upper echelons of Google Search—which is a bad omen for your overall click-through rate.
Solution: There is no shortcut for solving missing meta description tags. You should go through all of the flagged pages, confirm the need for a meta description, and try to come up with a creative, contextual, and impactful one for each page.
4.4 Pages have duplicate H1 and title tags
Problem: Your pages are getting flagged for having the same title and H1 tags.
This one may not be your fault, because some content management systems tend to duplicate the title and H1 heading in the first-level header without notifying the unsuspecting uploader.
This can trigger some spam alarms after the crawlers have finished analyzing the page.
Plus, using duplicate content in your page headers means that you’re potentially missing out on crucial keyword opportunities that could improve your visibility in the SERPs.
Solution: Go over the affected pages and update them with different copy for the title and H1 tags—and make them count!
4.5 Pages have too much or not enough text within the title tags
Problem: Search engines are truncating your titles that extend beyond 70 characters in length. This can make things iffy for your CTR, as users are less likely to click when they can’t see the full extent of what they’re clicking on.

On the flip side, having titles that contain fewer than 10 characters is also not ideal for SEO because they don’t provide sufficient information to describe the contents on the shown page.
Moreover, you’re also missing out on valuable keywords that could’ve been used to gain additional visibility in the SERPs.

Solution: Go through all of the affected pages and rewrite the title tags to contain between 10 and 70 characters.
4.6 Sitemap.xml not indicated in robots.txt
Problem: There’s a missing link between your robots.txt file and your sitemap.xml.
Without a sitemap.xml, search engines may not be able to find certain pages on your website. This is especially true for very large sites with tons of pages.
Solution: Open your robots.txt file and insert the location of your sitemap.xml. You can use Google Search Console to check if Googlebot has indexed it correctly.
4.7 Notices
Once again, notices are not considered urgent issues according to the Semrush report, but they are nonetheless useful pointers on where you should turn your focus after taking care of the errors and warnings on your site.
The most common notices you can encounter include:
- Links on a page have non-descriptive anchor text
- Links have no anchor text
- Pages are nested more than three clicks deep
- URLs contain a permanent redirect
- Pages are blocked from crawling
- Pages have only one inbound internal link
- Internal outgoing links returned a 403 code
- Resources are formatted as a page link
- Orphaned pages
5. Cancel the Free Trial
Once you’ve reaped all the benefits of the Semrush trial, do the following steps to cancel it before it runs out:
- Log into your Semrush account
- Navigate to https://www.semrush.com/cancel/
- Click Decline and unsubscribe
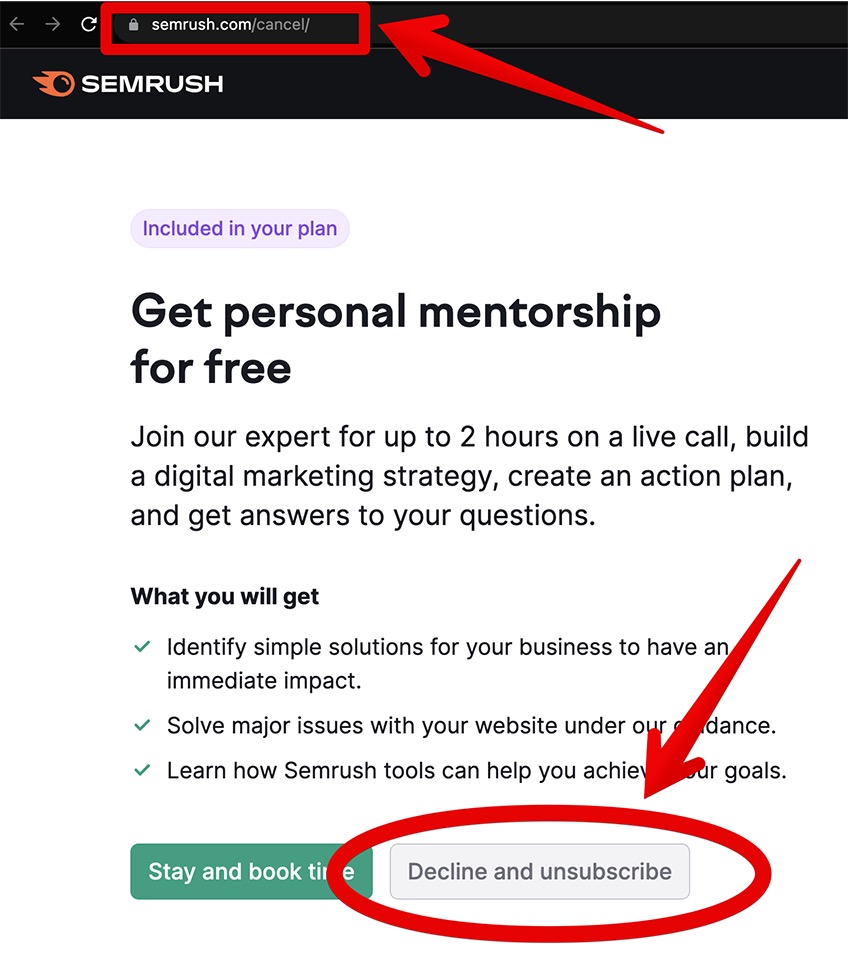
Then click Continue to cancel.
Pick your reason for canceling and click Continue.
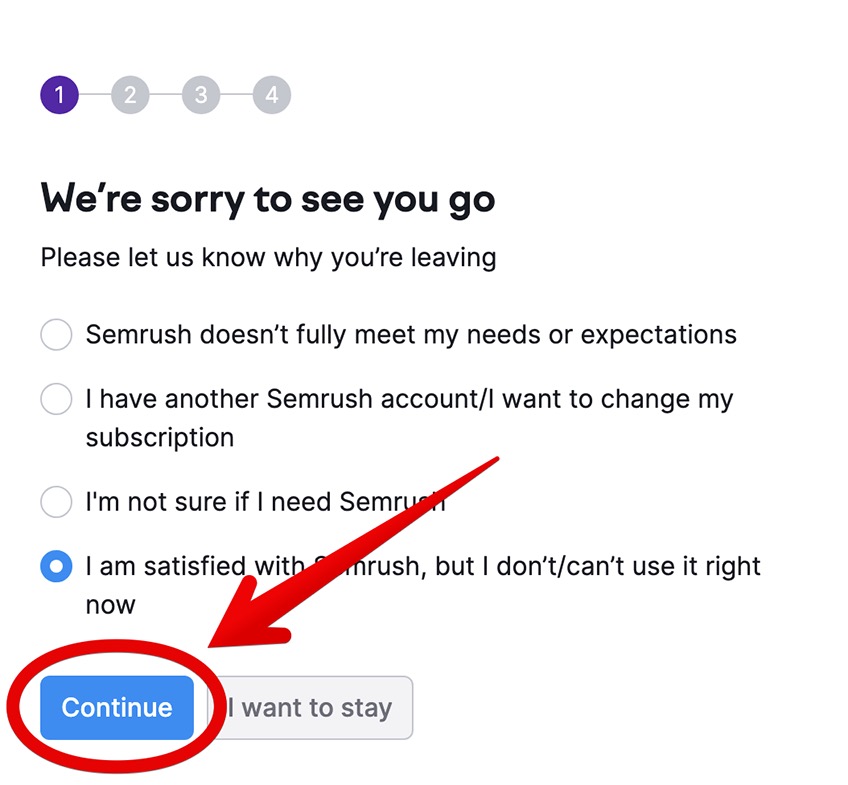
Proceed by clicking Continue until you land on the Cancel subscription screen.
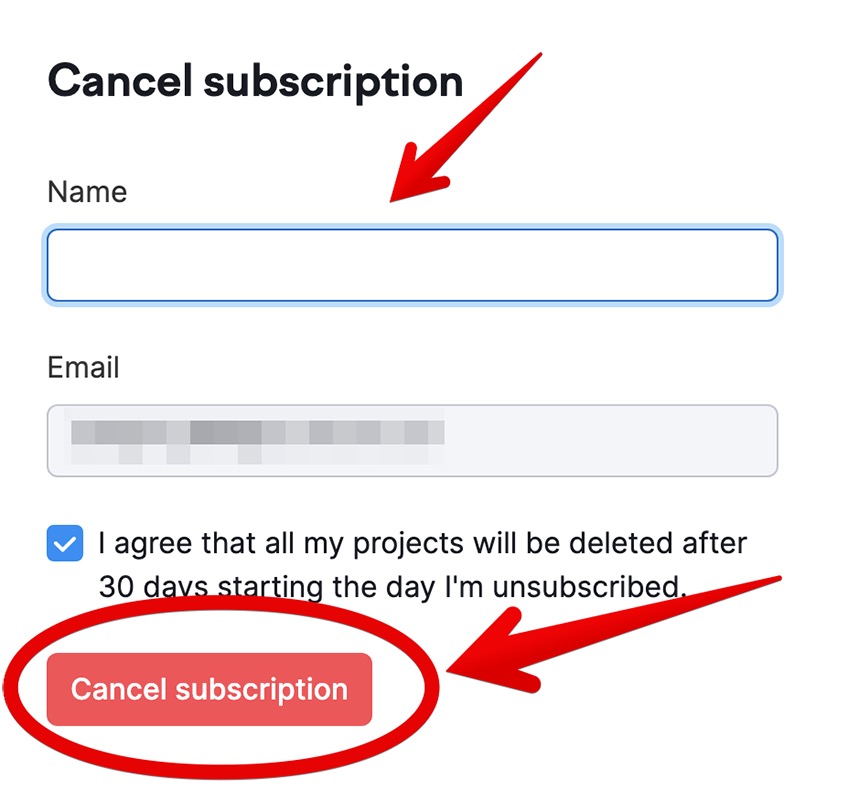
Enter your name, accept that your projects will be deleted 30 days after canceling your free trial, and click Cancel subscription.
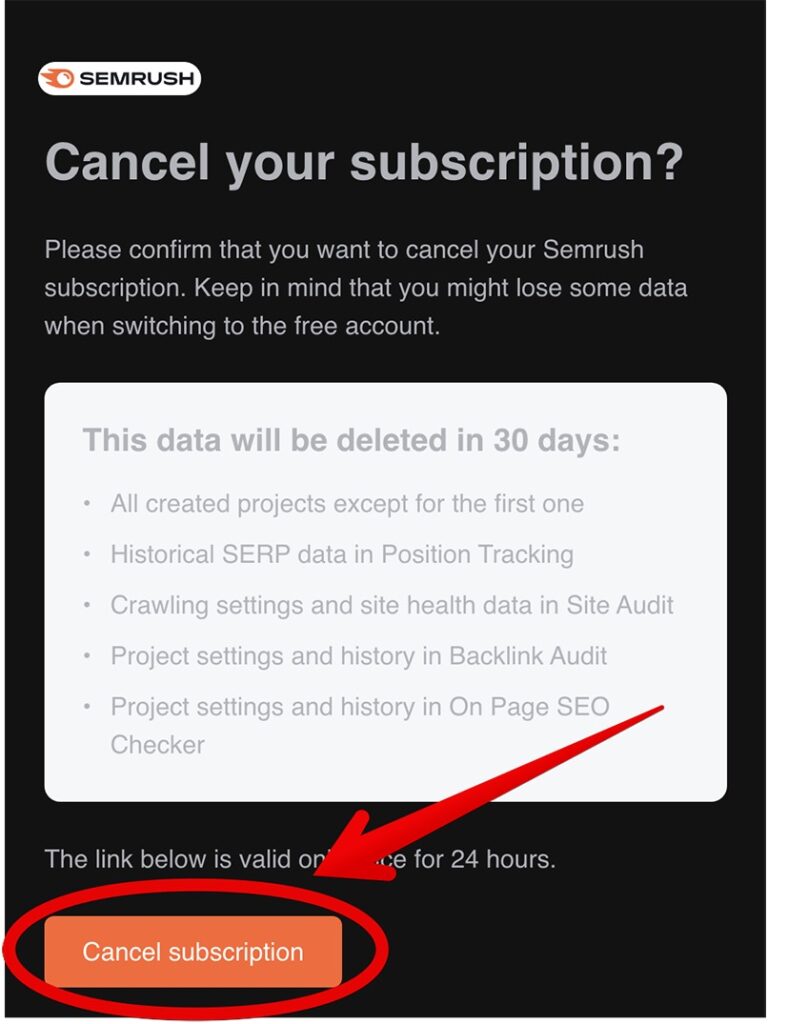
Finally, you will receive an email to confirm your cancellation. Click Cancel subscription.
You have successfully canceled your Semrush free trial plan.
What Factors Have the Most Impact on Website SEO Scores?
We’ve taken a cursory glance at some of the most common factors that impact website SEO scores, but there’s still a lot more to it.
In Semrush, some of the more granular factors are arranged in groups and can be accessed by clicking on the View Details buttons within Thematic Reports.
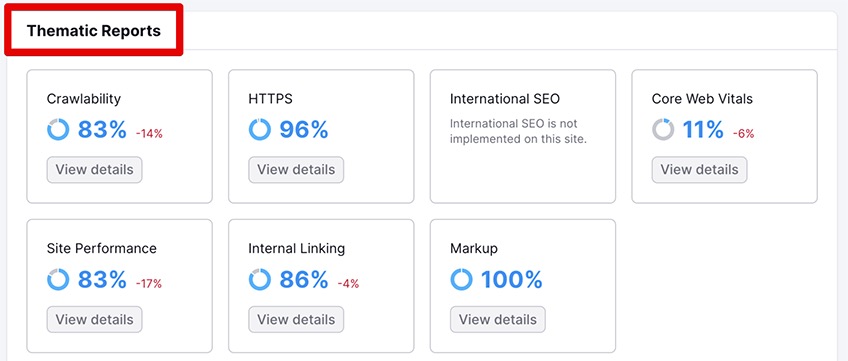
Each group contains several pertinent factors for website health. The errors, warnings, and notices contain tags that categorize them into specific groups—though one item can be a part of multiple groups.
The majority of these factors are universal across multiple tools, so they won’t really change if you decide to use a different tool instead of the Semrush website SEO audit.
1. Crawlability and Indexability
Crawlability and indexability are hands down the two most important factors that determine the outcome of your site health score.
In fact, most of the issues related to your SEO score will end up brushing shoulders with your site’s crawlability and indexability.
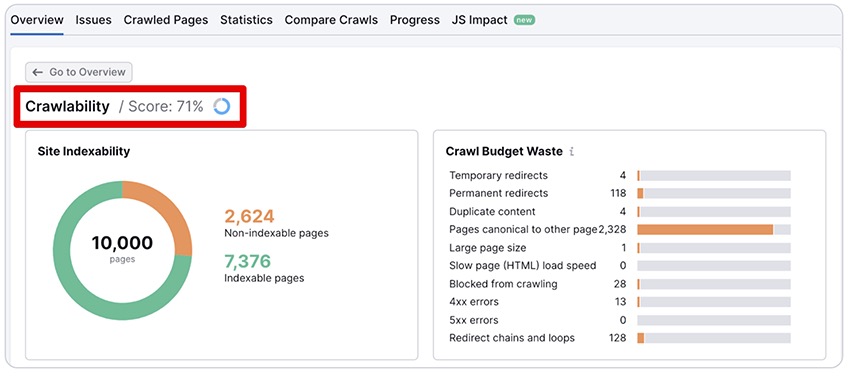
Crawlability refers to the level of freedom a search engine bot has while crawling your site, and that goes for both directions—from the bot to your site, and from your site to the crawler.
If you experience a low crawlability score, then it probably means your site has bigger structural issues that you need to address.
On the other hand, indexability comes into play after the search engine bot has crawled, analyzed, and indexed the page back into its database.
Contrary to popular belief, Google does not perform live searches whenever a user enters a query in the search bar. Instead, it scans its database and coughs up the most relevant results from what it has already indexed.
This is why non-indexed sites, pages, and other resources won’t show up in Google Search—but you can imagine the electricity bill and server costs of storing such a stupendous amount of additional data, right?
Anyhow, back to the important factors that fall under the crawlability and indexability umbrella.
1.1 Robots.txt
The robots.txt file is like a turnstile at the entrance of a subway station; passengers with tickets are allowed to pass through and make their way to the platform, but those without tickets will get stopped at the turnstile.
Imagine that the pages on your site are potential passengers. Those that carry tickets represent pages that are allowed to be crawled by search engine bots, and those that don’t are like pages that have been disallowed in the robots.txt file, so the bots won’t be able to crawl them.
The robots.txt file features several main parameters, including:
- User-agent: * – This indicates that the rules are meant for all search engine crawlers
- Allow:/people-with-tickets/ – This specifies that all resources (pages, images, other elements) in the /people-with-tickets/ directory are allowed to be crawled
- Disallow:/people-without-tickets/ – This instructs bots to avoid crawling that specific directory
Unwanted errors stemming from misused parameters in the robots.txt file are more common than you’d think, and it’s also true that a crawler will sometimes ignore your robots.txt directives and end up crawling directories that you specifically told it not to.
This can be puzzling, but it may also be completely innocuous in terms of your site’s overall SEO score. Either way, it’s still a good idea to check your robots.txt file frequently to avoid these rare cases.
1.2 Internal links
Internal links act as signposts that point web crawlers where to go, guiding them along your site and introducing shortcuts to save crawl budget.
Deciding where to place internal links on your site—including the choice of anchor text and the number of internal links on a single page—can be an art form in and of itself.
An easy rule to remember is to identify your best-performing pages for inbound traffic and use them as “main nodes,” per software engineering parlance.
Next, identify your most contextually relevant pages and then create internal links that lead to your main node pages.
In other words, your main node pages should receive the most inbound links from the largest amount of contextually relevant pages, while also spreading the love by linking back to other contextually relevant pages.
Finally, it’s also not a bad idea to create a spreadsheet for keeping track of your internal linking and update it regularly.
1.3 XML sitemap
The XML sitemap is exactly what it says it is—an organized map of your site that lists your pages as put together by the webmaster.
Sometimes, by chance or by accident, you may end up having orphan pages on your site.
An orphan page is a page that exists outside the nexus of your internal linking structure and thus cannot be reached by navigating through the hyperlinks from other pages. The only way to reach it is by locating its URL directly.
Since a well-optimized XML sitemap provides a significant boost to your crawlability and indexability scores, you may want to add orphan pages to your site hierarchy by introducing links to them. You can also add them to your XML sitemap and raise their chances of being discovered by web crawlers.
2. HTTPS and Security
Hypertext Transfer Protocol Secure (HTTPS) is a type of protocol that protects the communication between a site’s server and a user’s browser so that web visitors can view pages as safely as possible.
Closely associated with HTTPS is the so-called Secure Sockets Layer (SSL), which is another safety protocol that offers an encrypted connection between the website and the user.
Both HTTPS and SSL are the current industry standards for any type of web communication.
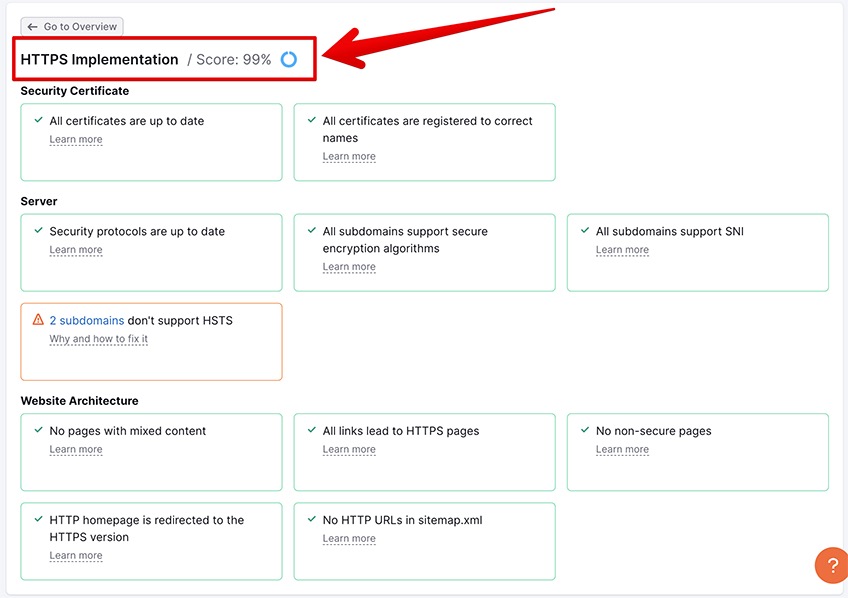
To achieve a successful score, you’ll need to be on the lookout for the following factors as outlined below.
2.1 Security certificate
If you don’t have an SSL certificate, or it is about to expire soon, consider getting a free certificate, renewing it, or contacting your providers to hook you up with a fresh one.
Most popular hosting services will automatically update your site with a free SSL certificate, but you can also buy a custom SSL certificate if you, like, really wanted to—but we, like, don’t recommend it.
2.2 Server security
If your site uses old, deprecated, or unsupported security encryption, this will negatively impact its UX and could lead to a decrease in search traffic.
That’s because most browsers will issue big fat warnings in bright red colors to let incoming users know that your site poses a potential security risk to their machines, which may cause users to click away and take a mental note not to visit your website in the future.
To avoid server security issues and their consequences, remember to update your security protocols, make sure that your subdomains support Server Name Indication, and look into implementing HTTP Strict Transport Security.
2.3 Website architecture
It’s possible that some elements on your website can still live outside of the confines of HTTPS, despite your site passing the HTTPS test.
The solution is to replace all unsecure HTTP elements with the latest HTTPS protocol.
This is also true for outbound links that lead to an HTTP resource, in which case you should replace it with a contextually similar HTTPS resource instead.
Another important issue that sometimes pops up is when an HTTP page contains one or more <input type=”password”> fields, which store user information in such an unsafe way that attackers could easily steal it and tarnish the reputation of your website indefinitely.
Thankfully, most modern hosting providers will boot up an HTTPS version of your domain by default, or they will at least give you the option to choose HTTPS over HTTP.
3. Core Web Vitals
Turning to advanced SEO, Core Web Vitals is a collection of standardized metrics developed by Google that help webmasters get a better understanding of what users experience when landing on a page.
In simple terms, Core Web Vitals generate metrics related to:
- Page loading performance
- Visual stability from the perspective of an end user
- Ease of navigation, interaction, and intuitiveness of UI
Three of those metrics in particular deserve closer inspection.
3.1 First Input Delay
First Input Delay (FID) measures the time it takes between a user’s input with an element on a page and that corresponding element’s response to that input. This metric is also known as input latency and is of particular interest to the competitive gamers of the world who can’t stand lag for a number of self-explanatory reasons.
Anyway, most modern websites face a dilemma that involves trying to serve up better content for users by using a collection of dynamic widgets, but that often comes at the expense of adding input latency. Nevertheless, a good rule of thumb to follow is that satisfactory FID scores are typically equal to or under 100 milliseconds, so shoot for that if you can.
The trick about having good FID scores comes from the difficulty to measure them accurately and uniformly, because objectively measured FID data can only be gathered when a website is live.
Your FID scores will also most likely be skewed from things that fall outside of your control, including the internet speed of users, the performance capabilities of their devices, and the serving speed of the hosting provider.
3.2 Largest Contentful Paint
The next Core Web Vitals metric of note is called Largest Contentful Paint (LCP). This measures the load time of different blocks of content that fall within the confines of the user’s screen, such as visual media.
It’s important to note that LCP does not measure load times of below-the-fold content, so anything the user has to scroll to see is not included.
You should aim for an LCP of 2.5 seconds counting from the time the page begins to load. Anything more than that and you run the risk of users deciding to bounce before the site finishes loading.
3.3 Cumulative Layout Shift
Have you ever tried to click on an organic result while performing some kind of search, only to end up inadvertently clicking on an ad that jumped in its way instead? You are not alone!
This is what Cumulative Layout Shift (CLS) deals with in a nutshell. It identifies elements on a page that change their initial position after the page has loaded in full.
Sometimes this happens unintentionally, but many times it happens because there are some clever grey hatters (cybersecurity experts and/or hackers who like to bend internet rules) that have figured out a way to earn additional per-click ad revenue by measuring the average time it takes for a user to click on a highly desirable page element, then designing their site to overlay or replace that element with an ad at the exact time a user typically goes to click on it.
It’s the perfect switcheroo, and we’ve all fallen for it more times than we’d like to admit, haven’t we?
Of course, an ethically sound website should minimize the occurrence of elements dancing around the site—after all, you are supposedly serving your audience valuable content, not the most frustrating experience of an impromptu whack-a-mole!
The ideal CLS shouldn’t clock in at more than 0.1 seconds.
4. Site Performance
The next big-ticket factor for SEO scores is site performance. To access this report in Semrush, click on the View Details button under the Site Performance heading.
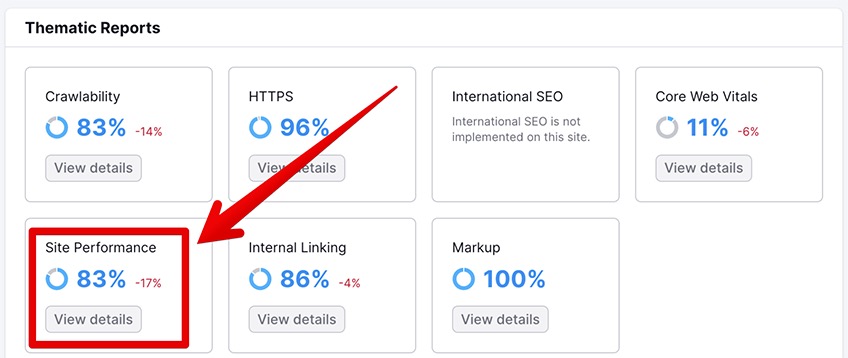
You will be led to a new dashboard where you can analyze all of your site’s performance issues, including errors, warnings, and the average page load speed as well.
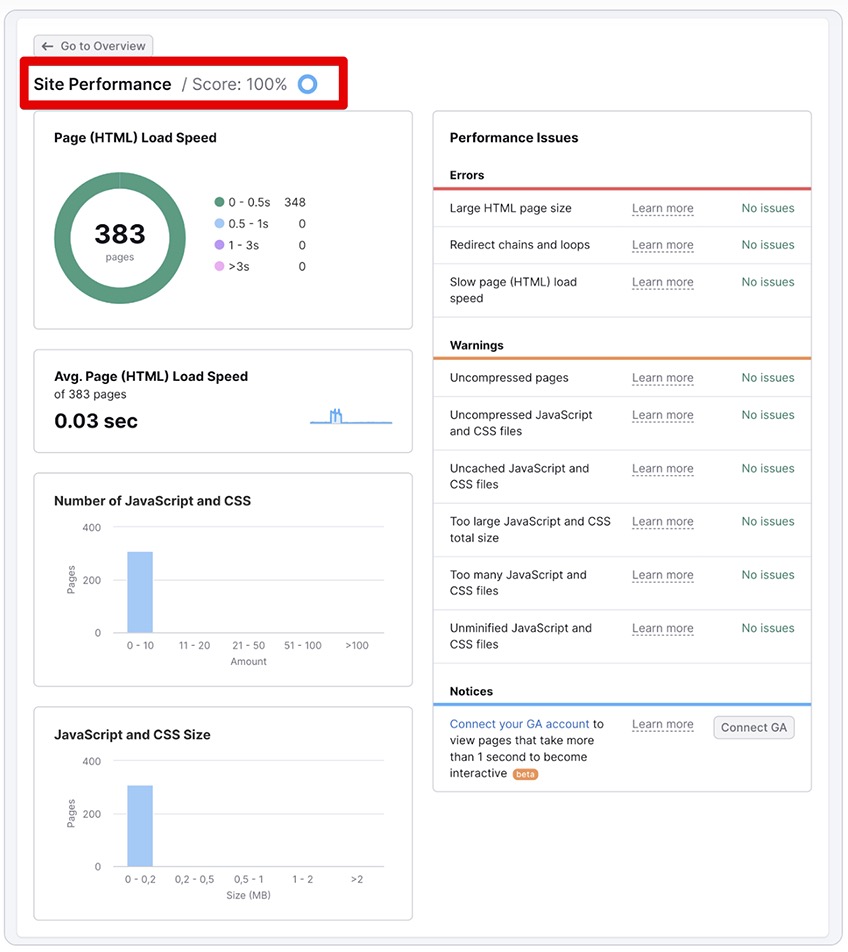
For site performance, three things matter the most: page size, redirects, and load speeds.
4.1 Large HTML page size
HTML page size consists of a given page’s code in its entirety. According to the latest web standards, a single page should not exceed 2 MB in total size.
A page that breaks this rule could lead to slower load times, which results in a bad UX and a significant drop in search rankings.
Fixing this issue would require you to dig through some of the code, analyze it, and remove any possible culprits such as redundant styles, inline scripts, or other elements that won’t impact the stability of the page if taken out.
4.2 Page redirects
When a site undergoes changes, redirecting from one page to another can be a quick solution that solves many issues at once. However, many of the dangers to quick solutions like this come in the form of incorrect implementation.
If URL redirects are done improperly, it can prove detrimental to your site’s performance.
One example of improper redirect implementation is known as a redirect loop. If your site sends the search engine bot on an infinite redirect loop, chances are the bot won’t get to crawl the important pages, as by that time it’ll get stuck and hit the threshold of your previously established crawl budget.
This is bad for SEO, bad for UX, and bad for the overall visibility of your site.
Another common example is redirect chains, where redirects happen in a finite chain rather than an infinite loop. The rule of thumbs here is to avoid using any more than three successive redirects so you can avoid encountering some of the same aforementioned problems.
Lastly, it’s important to be careful with the idea of completely removing redirects, as some pages may inadvertently get caught in the middle and end up as 404 errors.
4.3 Slow HTML page load speed
We know what page load speed means in the context of page size and code density, but it’s also relevant for other factors such as the optimization of web servers.
In short, if your web server is not servicing your visitors efficiently enough, your users will experience increased page load times—resulting in a poorer UX.
The obvious fix here is to contact your web hosting provider, analyze the issue, and choose a different hosting package if the existing one doesn’t fulfill the demands of your users. Transferring to a dedicated server is one way to go about it.
Additionally, there’s a host of other factors that may impact your server response times, including:
- Slow database queries
- Depleted CPU resources
- Slow application logic
- Depleted memory
- Slow frameworks and libraries
- Slow routing
To learn more, consider the latest page speed recommendations from our search engine overlords back at Google HQ.
Lastly, page load speed can also be negatively affected by uncached CSS and JavaScript files.
Browser caching allows modern browsers to reuse your page’s resources so that returning users won’t have to wait for their browsers to download them every time. Enabling browser caching in the response header is a simple fix that could improve your page load time significantly.
5. Internal Linking
Efficient internal linking is not a one-and-done remedy like enabling browser caching—it’s an ongoing SEO strategy that webmasters need to examine, implement, and update regularly.
The issues related to internal linking mostly stem from broken links and wrongly specified nofollow attributes, both of which deserving some further explanation.
5.1 Broken links
Whenever you change, delete, or add something to an existing URL, all of your website’s links pointing to that URL will now be pointing to a non-existing page—unless you update them.
Any that you miss become broken links.
Broken links come in two types, internal and external. Broken internal links lead the user to a nonexisting resource on the same website, whereas broken external links are found on the target website but lead the user to a nonexisting resource on a different website.
This can be problematic because visitors who click on a link that leads to a 404 error page— even if it’s on another website—can become frustrated and abandon yours.
For example, imagine going to a store and picking up the newest Barbie-themed chocolate because you fell for the latest Hollywood craze. (You wouldn’t do that, right? Because we totally didn’t.)
Now imagine the first pink wrapper you pick up ends up being empty on the inside—and the second one? Same thing.
How many empty Barbie wrappers are you willing to go through before you abandon the store altogether?
That’s basically what happens when search engine bots encounter heaps of broken links while trying to access your site. As a result, your SEO score suffers and your site gets relegated to the bench for bad behavior.

“Hypotheticals” aside, keep in mind that broken links can show up in the real world for a bunch of different reasons, including pure accidents.
For instance, if you simply forgot the S in HTTPS when modifying a link’s URL, or if there was a miscommunication between multiple collaborators on your site, or if your cat stepped on your keyboard when you weren’t looking, all of these hiccups can lead to broken links.
Some other common causes of broken links are:
- Site migration issues
- Deleted or moved pages
- Erroneously constructed URLs
- Broken JavaScript elements
- Malfunctioning forms
- Site-wide URL updates
- Removal of certain multimedia content
- Outdated third-party plugins
Thankfully, all of these issues are fixable—and a good trick for avoiding broken links in the future is to remember that each time a new broken link is given life, an angel’s left wing loses a feather.
To locate your site’s broken links, click the corresponding XX issues button for internal or external links.
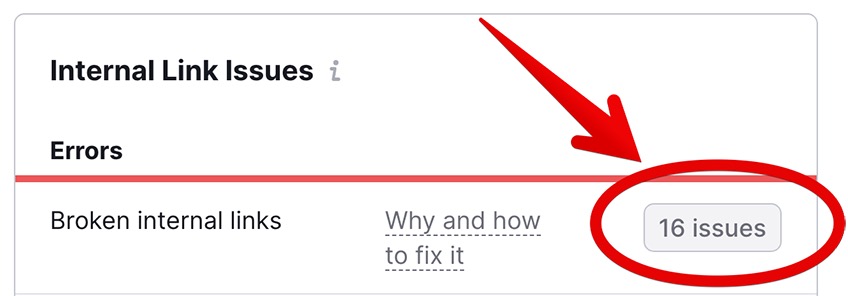
Once you’ve identified the main culprits, you can choose between the following remedies:
- Redirecting the broken link from a bad URL to the intended URL
- Updating the broken link from a misspelled URL to the correctly spelled URL
- Removing the link from the page entirely
5.2 Wrongfully specified nofollow attributes
The HTML structure of a hyperlink is simple but fairly customizable.
In the backend, an example link looks something like this:
- <a href=”example.com”>Anchor Text</a>
The a part is considered the tag that defines the link. Href is an attribute that points to where the link should go. The Anchor Text is what pops up as a visible, clickable link on the user’s end.
Links can have multiple attributes. One of these attributes is defined as rel=”nofollow” and its purpose is to tell search engine bots not to follow that link, thereby preventing the link from passing any link juice.
Link juice, also known as link authority, is a colloquial term that SEO professionals use to describe the value that some links carry within them over other links.
For example, a highly contextual link on a highly relevant page of a firmly established website will pass considerably more link juice than a non-contextual link from a relatively new website that has only been gracing the web with its presence for a few months.
A link featuring a rel=”nofollow” attribute looks like this:
- <a href=”example.com” rel=”nofollow”>Anchor Text</a>
When implemented correctly, the rel=”nofollow” attribute should prevent passing any link juice to or from undesirable sources. In theory.
In practice, Googlebot may decide to ignore the rel=”nofollow” attribute and follow the link anyway. Why or how this is done continues to puzzle the SEO community.
Logically, if you end up using the rel=”nofollow” attribute in your internal links, you will prevent the link juice from being properly distributed across your site.
But alas, the link juice must flow.
The solution to this is fairly simple, though it may be time-consuming depending on the number of affected links.

You can identify and remove the wrongly specified nofollow attributes by clicking the XX Issues button on the right-hand side of the Nofollow attributes in the outgoing internal links part, or its equivalent in your SEO score tool of choice.
6. Markup
We briefly touched on the subject of structured data before, which is an umbrella term that encompasses three of the top markup formats:
- Microdata
- JSON-LD
- RDFa
These formats are used to create Google-recognizable markup data to display rich results in the SERPs.
As a result, wrongfully implemented or missing markup items could cost your website valuable search traffic down the road.
Currently, Google recognizes 31 structured data items, such as:
- Breadcrumb—Rich results for better site navigation
- Event—Interactive search result that shows upcoming events like music festivals
- JobPosting—Interactive rich data card that features logos, ratings, job reviews, and more
- Logo—A business logo that shows up in the search results
- Movie—A comprehensive carousel that provides movie details
In the future, the number of these items may grow or shrink depending on the productivity level of Google engineers and Schema enthusiasts.
To enable structured data, you’ll need to implement Schema code. The code has to be implemented on the specific page for it to show up later as a rich data card in the SERPs.
Most popular website SEO score tools support some or all of the current markup formats. Semrush, for instance, supports Microdata and JSON-LD, but not RDFa.
To access the markup section in Semrush, click View Details under the Markup heading in your site audit dashboard..
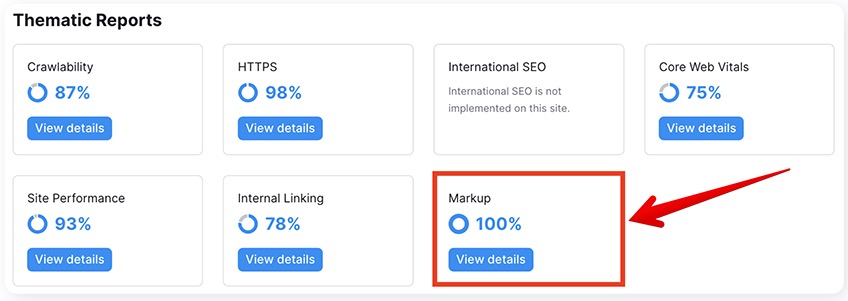
This will take you to a more detailed markup analysis.
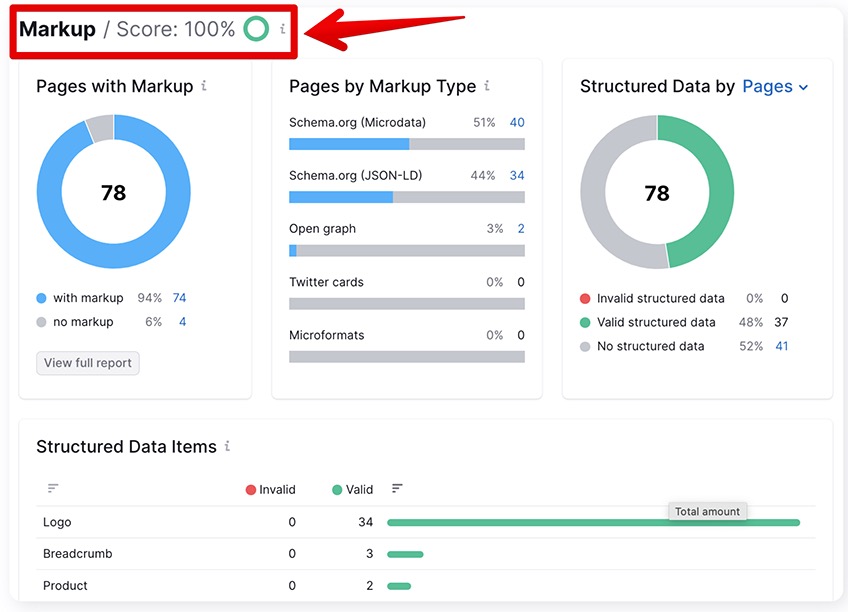
Since there is a slight difference between the Google and Schema.org structured data vocabularies, Semrush might not recognize all rich data items.
Similarly, your markup analysis might be somewhat incomplete when using other tools as well.
Fortunately, you can fill the gaps by using Google’s rich results test tool. All hail the big G.
7. International SEO
If you are running a multilingual website or you want to expand your business operations to other countries—then you’ll definitely want to take a deeper look at international SEO.
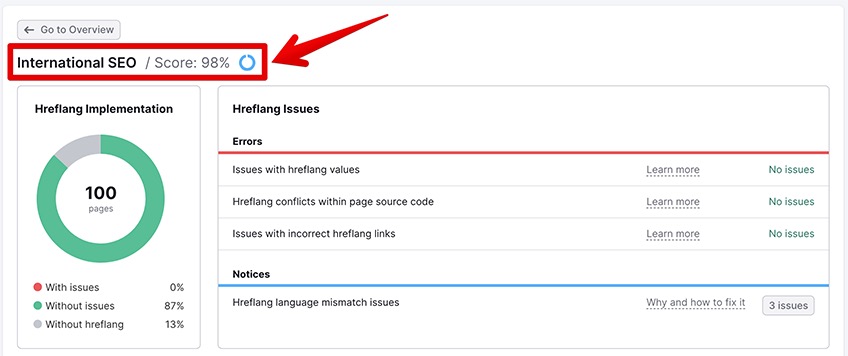
For the most part, international SEO scores have to do with the implementation of the “hreflang” tag, which is used to tell Google which pages should be served depending on the user’s location and their preferred language settings.
Here are some of the most common hreflang errors.
7.1 Issues with hreflang values
During an international SEO site audit, your pages will be hit with an error when one or two of these things are true:
- You have not correctly implemented the SO 639-1 format in your language code
- Your country code doesn’t follow the ISO_3166-1_alpha-2 format
For example, if you’re operating globally but want to serve a specially-tailored version of your site to British users, consider adding both of the following hreflang tags:
- https://youraweasomesite.com/” hreflang=”en” />
- https://youraweasomesite.com/” hreflang=”en-GB” />
Here’s a handy list of two-letter ISO-639-1 codes to refer to if you’re not sure which hreflang code to use.
7.2 Hreflang conflicts in the page source code
This one is tricky. Again, if you run a multilingual site, it’s important to serve the proper site version to your audience from the corresponding geographical area.
To do this, you should consider integrating the rel=”alternate” hreflang=”lang_code” attribute where needed, and in the right way.
However, if your source code isn’t properly synchronized with any existing hreflang attributes, chances are search engines won’t display the correct language version of your site—thus thwarting your international SEO efforts for good.
Conflicts between your page’s source code and the hreflang attributes can arise from three main reasons:
- Inconsistencies between rel=”canonical” URLs and hreflang attributes
- Inconsistent hreflang URLs
- Hreflang URLs that are not self-referenced
7.3 Issues with incorrect hreflang links
Hreflang links should always send your users to HTTP 200 status code URLs.
If not, search engines will wrestle with a high probability of misinterpreting the hreflang links and, correspondingly, may end up serving pages with the incorrect language to your international visitors.
Here are three suggestions for proper hreflang link integration:
- Analyze and repair incorrect hreflang redirects
- Identify and repair broken hreflang URLs
- Swap relative URLs with absolute URLs
For true students of the craft, take a closer look at this international SEO resource for an in-depth look of correct hreflang implementation as explained by Google.
Maintaining That Perfect SEO Website Score
Getting and (more importantly) keeping a perfect website SEO score is a big investment of time, resources, and effort—but it can all be worth it in the end.
A fully search-optimized site is akin to a big, juicy honker of a golden goose that cranks out golden eggs as fast as Mattel cranks out Barbie dolls.
That’s because a perfectly optimized site is a harbinger of many boons, including:
- Bumps in organic search traffic
- Increased brand awareness
- Solidified trust with your readers
- Improved chances to generate new leads
- Competitive advantages over your market peers
So whatever you do, if you ever get your hands on a perfect SEO score, do not slay that golden goose.
For additional information on similar topics, check out our guide on technical SEO, our simple SEO guide, or our extensive review of the best SEO tools out there today.